Mockito is an unwrap source testing framework for Java released under the MIT License. The framework allows the creation of test double objects (mock objects) inautomated unit tests for the purpose of Test-driven Development (TDD) or Behavior Driven Development (BDD).
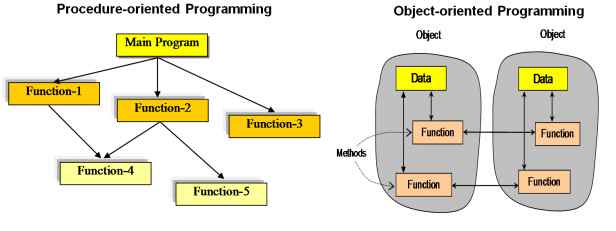
Unit testing is used to test a single programming unit Ex: a class or a method, in-fact almost every Java developer write unit test on per method basis. The Stub and Mock objects are two concepts, which helps during unit testing, they are not real world objects, but act like real world objects for unit testing purpose.
The common testing for approach to test a unit, which depends on other unit is by using Stubs and Mock objects. They help to reduce complexity, which may be require to create actual dependent object. In this tutorial, we will learn few basic difference between Stub and Mock object in Java Unit testing. This post is rather small to tackle this whole topic, at best it just provide an introduction.
JUnit is the most popular framework for unit testing Java code. I am assuming you can download Mockito and get it in your classpath. So I'll start with tests that implement some of the requirements from here (https://code.google.com/p/mockito/downloads/list). However, in a nutshell:Download mockito-all-1.7.jar from here. Create a new Java project in your favorite IDE Add that jar to your project's classpath, Add JUnit 4 to your project's classpath. More Examples( https://code.google.com/p/mockito/ )
Mockito API: http://docs.mockito.googlecode.com/hg/latest/org/mockito/Mockito.html )

package com.mockito;
import java.io.IOException;
import java.io.OutputStream;
import java.io.OutputStreamWriter;
import java.util.Iterator;
import java.util.List;
import org.hamcrest.BaseMatcher;
import org.hamcrest.Description;
import org.junit.Assert;
import org.junit.Test;
import org.mockito.Mockito;
/**
* I am assuming you can download Mockito and get it in your classpath.
* So I'll start with tests that implement some of the requirements from here
* (https://code.google.com/p/mockito/downloads/list).
* However, in a nutshell:Download mockito-all-1.7.jar from here.
* Create a new Java project in your favorite IDE Add that jar to your project's classpath,
* Add JUnit 4 to your project's classpath
* More Examples( https://code.google.com/p/mockito/ )
* Mockito API ( http://docs.mockito.googlecode.com/hg/latest/org/mockito/Mockito.html )
* @author Myjavacafe
*/
public class MockitoTest {
public static void main(String[] args) {
// TODO Auto-generated method stub
}
/**
* This example creates a mock iterator and makes it return “Hello” the first time method
* next() is called. Calls after that return “World”. Then we can run normal assertions.
*/
@Test
public void iterator_will_return_hello_world() {
// arrange
Iterator i = Mockito.mock(Iterator.class);
Mockito.when(i.next()).thenReturn("Hello").thenReturn("World");
// act
String result = i.next() + " " + i.next();
// assert
Assert.assertEquals("Hello World", result);
}
/**
* Its creates a stub Comparable object and returns 1 if it is compared to
* a particular String value (“Test” in this case).
*/
@Test
public void with_arguments(){
//Set the class to mockito
Comparable c = Mockito.mock(Comparable.class);
//Set the values to mockito object
Mockito.when(c.compareTo("Test")).thenReturn(1);
//set the
Assert.assertEquals(1,c.compareTo("Test"));
}
/**
* The method has arguments but you really don’t care what gets passed or cannot predict it,
* use anyInt() (and alternative values for other types.
* This stub comparable returns -1 regardless of the actual method argument.
*/
@Test
public void with_unspecified_arguments(){
Comparable c = Mockito.mock(Comparable.class);
Mockito.when(c.compareTo(Mockito.anyInt())).thenReturn(-1);
Assert.assertEquals(-1,c.compareTo(6));
}
/**
* The syntax is doReturn(result).when(mock_object).void_method_call();
* Instead of returning, you can also use .thenThrow() or doThrow() for void methods.
* This example throws an IOException when the mock OutputStream close method is called.
*/
@Test(expected=IOException.class)
public void OutputStreamWriter_rethrows_an_exception_from_OutputStream()
throws IOException{
OutputStream mock = Mockito.mock(OutputStream.class);
OutputStreamWriter osw=new OutputStreamWriter(mock);
Mockito.doThrow(new IOException()).when(mock).close();
osw.close();
}
/**
* We verify easily that the OutputStreamWriter rethrows the exception of the wrapped output stream.
* To verify actual calls to underlying objects (typical mock object usage),
* we can use verify(mock_object).method_call; This example will verify that OutputStreamWriter
* propagates the close method call to the wrapped output stream.
*/
@Test
public void OutputStreamWriter_Closes_OutputStream_on_Close()
throws IOException{
OutputStream mock = Mockito.mock(OutputStream.class);
OutputStreamWriter osw=new OutputStreamWriter(mock);
osw.close();
Mockito.verify(mock).close();
}
/**
* We can’t mix literals and matchers, so if you have multiple arguments they all have to be either
* literals or matchers. Use eq(value) matcher to convert a literal into a matcher that compares on value.
* Mockito comes with lots of matchers already built in, but sometimes you need a bit more flexibility.
* For example, OutputStreamWriter will buffer output and then send it to the wrapped object when flushed,
* but we don’t know how big the buffer is up front. So we can’t use equality matching.
* However, we can supply our own matcher.
*/
@Test
public void OutputStreamWriter_Buffers_And_Forwards_To_OutputStream()
throws IOException{
OutputStream mock = Mockito.mock(OutputStream.class);
OutputStreamWriter osw=new OutputStreamWriter(mock);
osw.write('a');
osw.flush();
// can't do this as we don't know how long the array is going to be
// verify(mock).write(new byte[]{'a'},0,1);
BaseMatcher arrayStartingWithA=new BaseMatcher(){
// check that first character is A
@Override
public boolean matches(Object item) {
byte[] actual=(byte[]) item;
return actual[0]=='a';
}
@Override
public void describeTo(Description description) {
// TODO Auto-generated method stub
}
};
// check that first character of the array is A, and that the other two arguments are 0 and 1
Mockito.verify(mock).write((byte[]) Mockito.argThat(arrayStartingWithA), Mockito.eq(0),Mockito.eq(1));
// Mockito.verify(mock).write(Mockito.eq(0));
}
}
Do you want to download this example, please
Click Me
Do you want to know more about Mockito, please
Click Me Do you want to know more about SprignBoot MicroServices Mockito
ClickMe